- Published on
MLOps Basics [Week 10]: Summary
- Authors

- Name
- Raviraja Ganta
- @raviraja_ganta


Note: Majority of the content and some diagrams are taken from Google whitepaper on MLOps. It's highly recommended to go through that. Paper link
What is MLOps?
There are many of defining MLOps. Few of the definitions are:
DevOps and DataOps have been widely adopted as methodologies to improve quality and reduce the time to market of software engineering and data engineering initiatives. With the rapid growth in machine learning (ML) systems, similar approaches need to be developed in the context of ML engineering, which handle the unique complexities of the practical applications of ML. This is the domain of MLOps. MLOps is a set of standardized processes and technology capabilities for building, deploying, and operationalizing ML systems rapidly and reliably. Source: Google
The extension of the DevOps methodology to include Machine Learning and Data Science assets as first-class citizens within the DevOps ecology. Source MLOps SIG
Regardless of the definitions, The goal of MLOps is to reduce technical friction to get the model from an idea into production in the shortest possible time to market with as little risk as possible.
Why MLOps Matter?
Successful deployments, adapting to changes, effective error handlings are the bottlenecks for getting value from AI.
72%of a cohort of organizations that began AI pilots before 2019 have not been able to deploy even a single application in production.Algorithmia’s survey of the state of enterprise machine learning found that
55%of companies surveyed have not deployed an ML model. i.e 1 in 2 companies.
Models don’t make it into production, and if they do, they break because they fail to adapt to changes in the environment.
Source: Google
MLOps Lifecycle
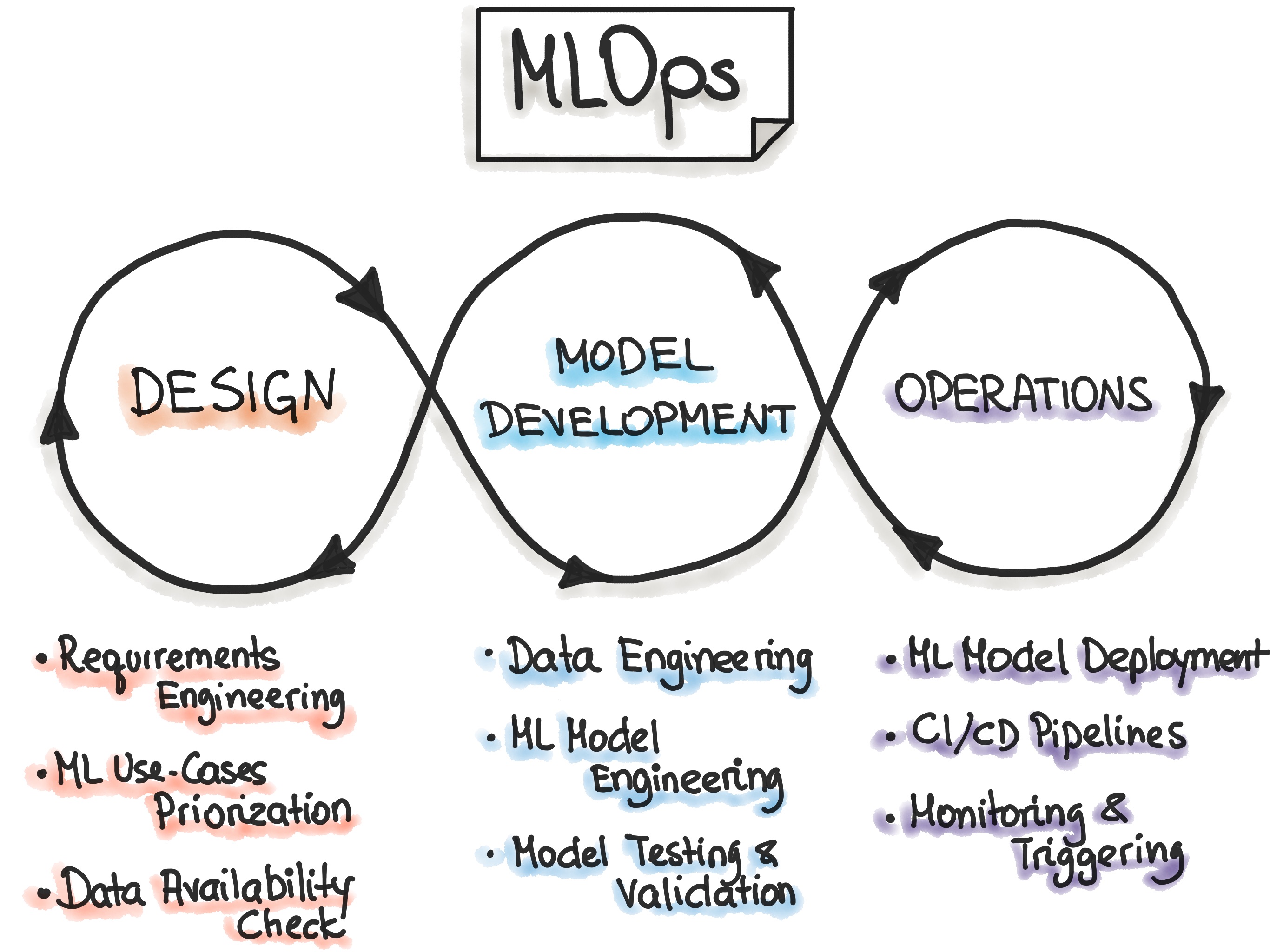
The MLOps lifecycle encompasses seven integrated and iterative processes:

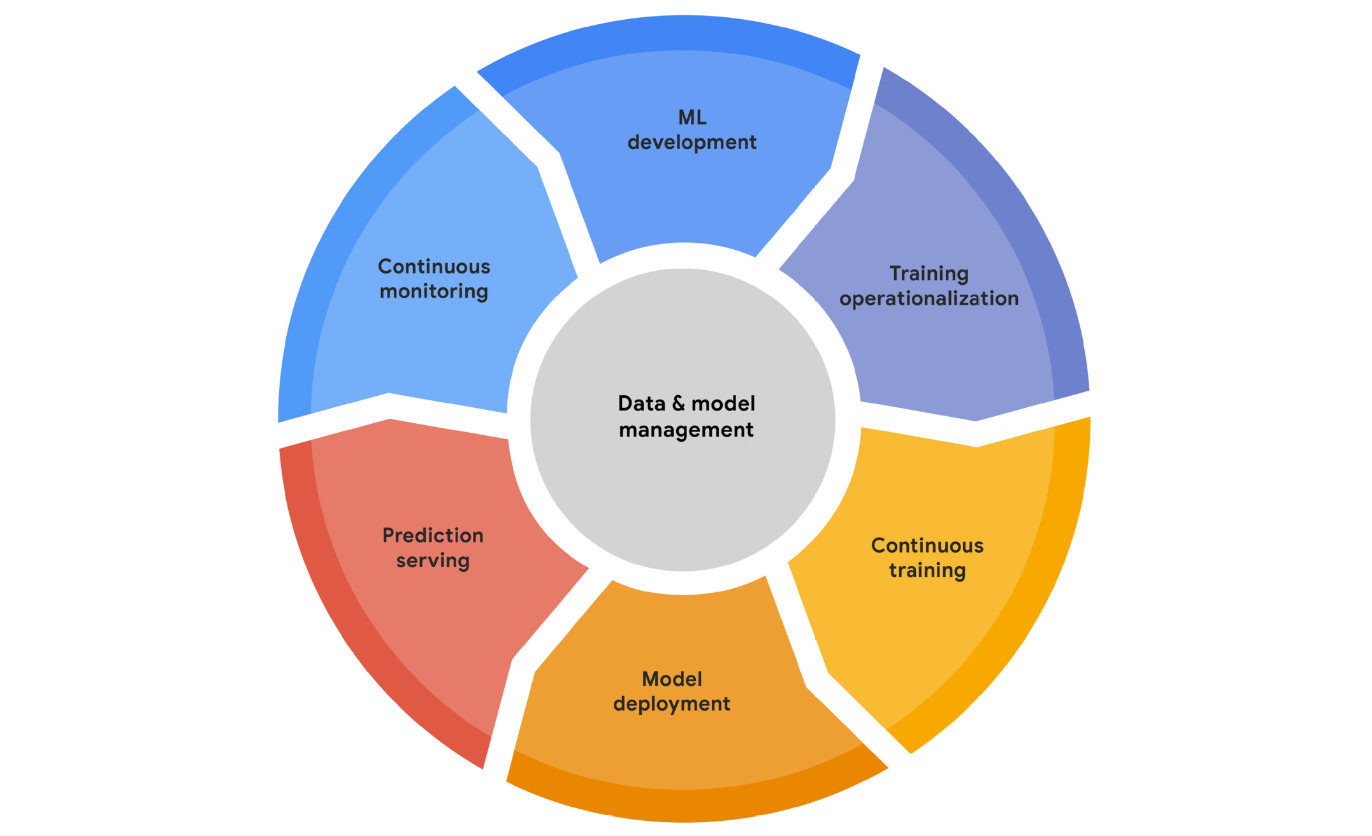
ML developmentconcerns experimenting and developing a robust and reproducible model training procedure (training pipeline code), which consists of multiple tasks from data preparation and transformation to model training and evaluation.Training operationalizationconcerns automating the process of packaging, testing, and deploying repeatable and reliable training pipelines.Continuous trainingconcerns repeatedly executing the training pipeline in response to new data or to code changes, or on a schedule, potentially with new training settings.Model deploymentconcerns packaging, testing, and deploying a model to a serving environment for online experimentation and production serving.Prediction servingis about serving the model that is deployed in production for inference.Continuous monitoringis about monitoring the effectiveness and efficiency of a deployed model.Data and model managementis a central, cross-cutting function for governing ML artifacts to support auditability, traceability, and compliance. Data and model management can also promote shareability, reusability, and discoverability of ML assets.
Putting it all together

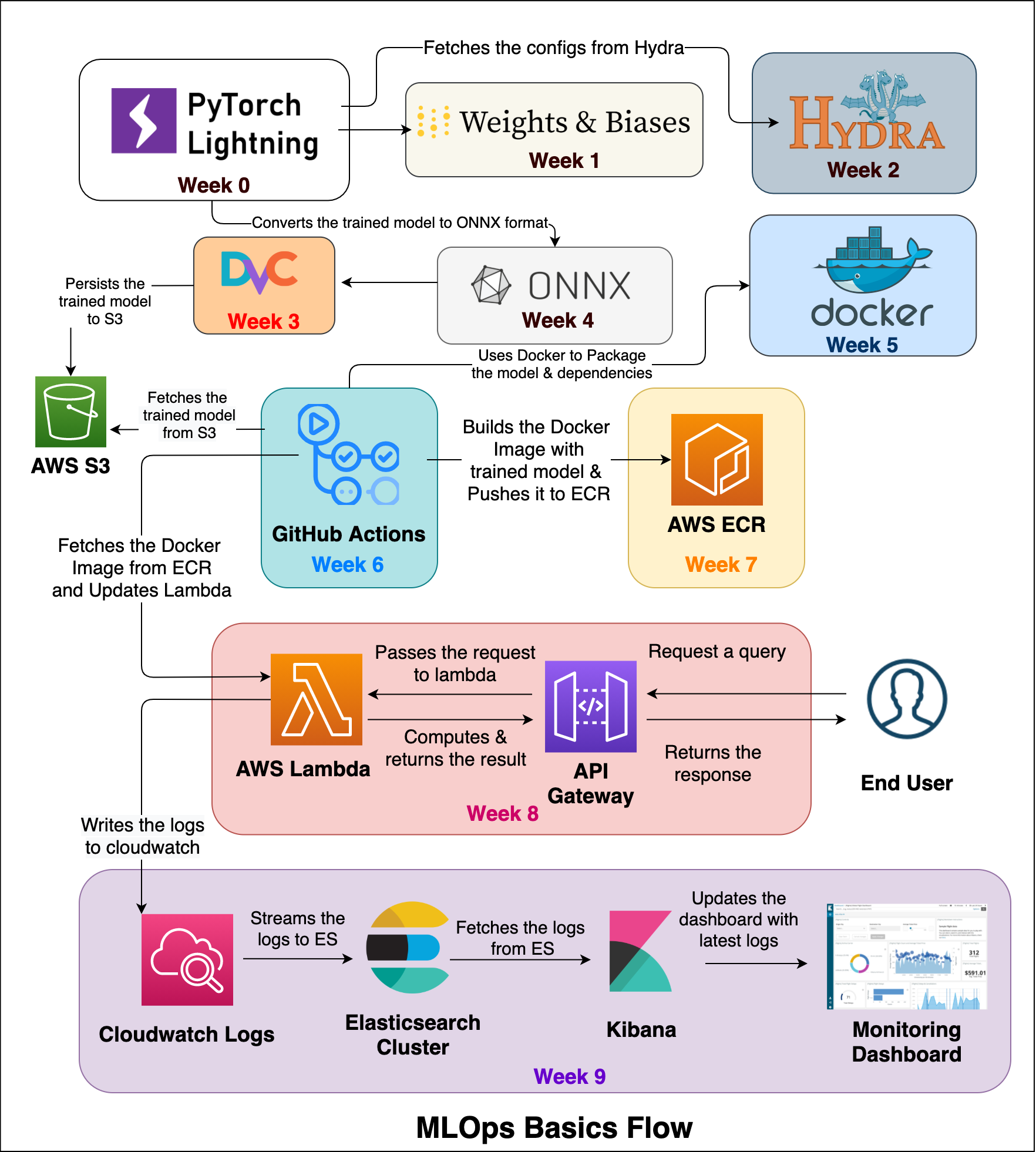
Things I have covered:
Week 0: ML development using PytorchLightning: Model developement is the core activity. There are many things to take care of. What is the task? What is the evaluation metric? What is relevant data? What are the training requirements? In the post, I have explored how to use
Pytorch Lightningfor model development.Week 1: Continous training (monitoring) using WandB: Tracking all the experiments like tweaking hyper-parameters, trying different models to test their performance and seeing the connection between model and the input data will help in developing a better model. In this post, I have explored how to use
Weights and Biastool for doing all that.Week 2: ML development (configurations) using Hydra: Configuration management is a necessary for managing complex software systems. Lack of configuration management can cause serious problems with reliability, uptime, and the ability to scale a system. In this post, I have explored how to use
Hydratool for doing that.Week 3: Data and Model management using DVC: Classical code version control systems are not designed to handle large files, which make cloning and storing the history impractical. Which are very common in Machine Learning. In this post, lI have explored how to use
DVCfor doing version controlling of models and data.Week 4: Model deployment (packaging) using ONNX: Models can be built using any machine learning framework available out there (sklearn, tensorflow, pytorch, etc.). We might want to run in a different framework (trained in pytorch, inference in tensorflow). A common file format will help a lot. In this post, I have explored how to use
ONNX.Week 5: Model deployment (packaging) using Docker: We might have to share our application with others, and when they try to run the app most of the time it doesn’t run due to dependencies / OS related issues. In this post, I have explored how to use
Dockerfor packaging.Week 6: Training Operationalization using GitHub Actions: CI/CD is a coding philosophy and set of practices with which you can continuously build, test, and deploy iterative code changes. This iterative process helps reduce the chance that you develop new code based on buggy or failed previous versions. With this method, you strive to have less human intervention or even no intervention at all, from the development of new code until its deployment. In this post, I have explored how to use
GitHub Actionsfor continous development.Week 7: Model depolyment (deploying) using ECR: Developers, testers and CI/CD systems need to use a registry to store images created during the application development process. Container images placed in the registry can be used in various phases of the development. In this post, I have explored how to use
AWS ECRfor doing that.Week 8: Prediction Serving using Serverless Lambda: A serverless architecture is a way to build and run applications and services without having to manage infrastructure. The application still runs on servers, but all the server management is done by third party service. In this post, I have explored how to use
AWS Lambdafor serverless deployment.Week 9: Continous Monitoring with Kibana: Monitoring systems can help give us confidence that our systems are running smoothly and, in the event of a system failure, can quickly provide appropriate context when diagnosing the root cause. In this post, I have explored how to use
Kibanafor prediction monitoring.
Next Steps
These are only basics. To get more experience in MLOps, I think following things can be explored:
Different ways of updating the model (Blue Green, Canary, A/B Test etc.)
Different ways of serving the model & serving multiple models (Torchserve, KFServing, Seldon, TensorRT etc)
Different things to monitor on the deployed model (Data Drift, Concept Drift, Continuous Evaluation, Error Rates)
Automating cloud configuration using IaaC tools (SAM, Terraform, Serverless Framework etc)
Data Orchestration pipelines (Dagshub, Dagster, Prefect etc)
Testing of code and models (PyTest, TextAttack etc.)
Resources
There are many resources now a days on MLOps. Some of them are:
🔚
This concludes the post. Hope my journey of exploring the basics of MLOps helped you. Keep Learning!!!
Code for MLOps-Basics Github